Heute?
Workshop II - 14.03.
Onboarding
Ersten Workshop gut überstanden?
Noch Fragen, die in der Zwischenzeit entstanden sind?
Mitnahme vom ersten Teil
KI ist nix neues
KI benötigt Definition
KI verlangt Nachfragen
Wie war das noch?
Unesco-Definition
"Systeme der Künstlichen Intelligenz sind in der Lage, Daten und Informationen auf eine Weise zu verarbeiten, die menschlichen Denkprozessen ähnelt oder diese nachzuahmen scheint. Dies beinhaltet Aspekte des Denkens und Lernens, der Wahrnehmung, Vorhersage, Planung oder Steuerung.EU-Definition (1)
"Künstliche Intelligenz ist die Fähigkeit einer Maschine, menschliche Fähigkeiten wie logisches Denken, Lernen, Planen und Kreativität zu imitieren."
EU-Definition (2)
"KI ermöglicht es technischen Systemen, ihre Umwelt wahrzunehmen, mit dem Wahrgenommenen umzugehen und Probleme zu lösen, um ein bestimmtes Ziel zu erreichen. Der Computer empfängt Daten (die bereits über eigene Sensoren, zum Beispiel eine Kamera, vorbereitet oder gesammelt wurden), verarbeitet sie und reagiert."
EU-Definition (3)
"KI-Systeme sind in der Lage, ihr Handeln anzupassen, indem sie die Folgen früherer Aktionen analysieren und autonom arbeiten."
KI? Nix neues!
"Das „Neue“ an der KI in den frühen 2010er-Jahren waren nicht Innovationen beim maschinellen Lernen. Diese Methoden stammen großteils aus den 1980er-Jahren. Neu waren hingegen zum einen die beträchtlichen Datenmengen, die zum Trainieren von KI-Modellen verwendet wurden."
Meredith Whittaker; Gastbeitrag auf netzpolitik.org.
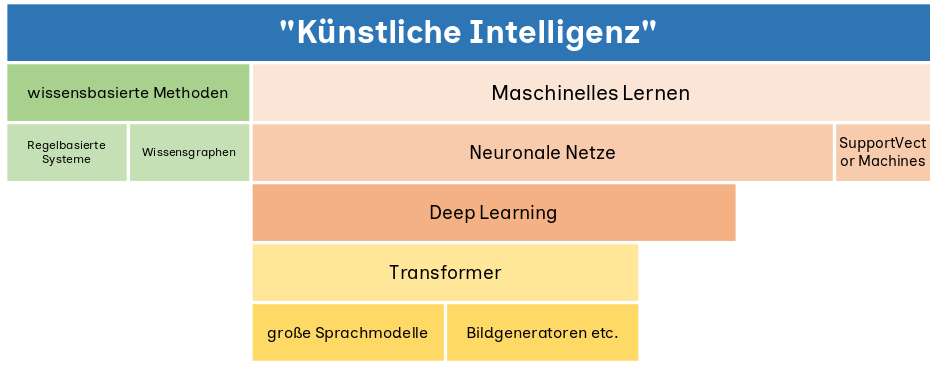
Fokus heute - die rechte Säule
Wir schauen etwas genauer hin, wie die Modelle die Welt wahrnehmen (und berechnen).
Wir schauen auf die Einflussgrößen.
Und beantworten die Frage: "Macht KI Fehler?".
kurzer Rückblick: Neuronale Netze
Neuronale Netze sind der Versuch, die Struktur des menschlichen Gehirns und seiner Funktion nachzubilden.

Aber wie funktionieren Sprachmodelle?
... und andere 'generative' Modelle
Aber was heißt das?
Beginnen wir mit der Tokenisierung.
Tokenisierung bezeichnet in der Computerlinguistik die Segmentierung eines Textes in Einheiten der Wortebene (manchmal auch Sätze, Absätze o. Ä.)
Wird gleich verständlicher!
Schauen wir uns an, wie das geht! Link Tokenisierung.
OK, und dann?
Die Tokens werden mathematisch in einen Bezug zueinander gesetzt.
Dabei werden die einzelnen Tokens auf 'Vektoren' abgebildet.
Vereinfacht gesagt werden die Tokens in einen Wahrscheinlichkeitsbezug zueinander gesetzt.
Der Begriff dafür ist Embedding (Einbettung)
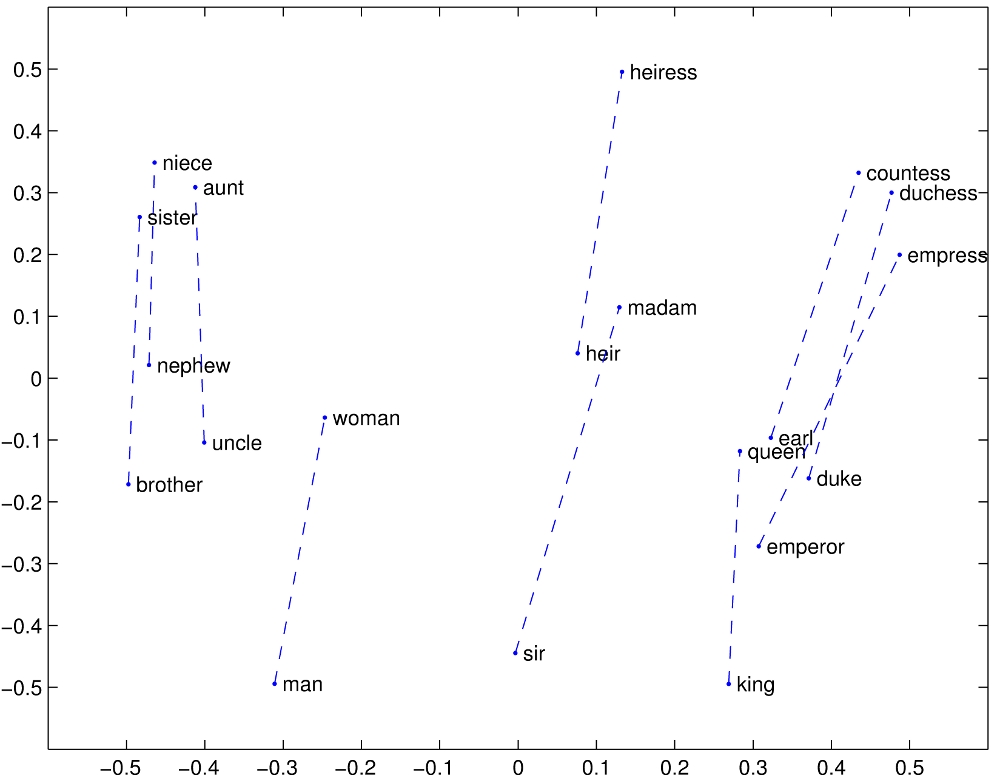
An der Stellung in diesem 'Koordinatensystem' erkennt man jeweils die Nähe zum gleichen Wort und zu anderen Wortpaaren.
Mit diesen 'Koordinaten' lässt sich rechnen.
Das passiert natürlich nicht graphisch und zweidimensional wie hier dargestellt sondern mathematisch mehrdimensional.
Wie entstehen dann die Ergebnisse?
Bis hierhin kann man sich das noch gut vorstellen - aber jetzt wird es leider etwas komplex.
Dafür machen wir einen Exkurs und auch wenn das jetzt alles erst mal weit weg von 'KI' klingt - wir kommen dahin zurück.
Eine Bekannte will ein Haus kaufen – wir sollen ihr helfen.
Sie hat ein Angebot bekommen: Ein Haus mit einer Fläche von 2000 Quadratfuß (rund 185 qm) soll 400.000 Dollar kosten.
Ist das ein guter Preis?
Wie sollen wir das entscheiden? Welche Informationen brauchen wir für eine Aussage dazu?
Die einfachste Antwort: Vergleichen.
Wir besorgen uns also von anderen Freunden oder aus Anzeigen weitere Hauspreise im selben Viertel.
Drei weitere bekommen wir:
Was machen wir mit den Informationen?
Idee: Wir errechnen den Durchschnittspreis pro Quadratmeter(oder Fuß) und bekommen eine erste Einschätzung.
Mit einfachem Dreisatz kommen wir bei den drei Vergleichshäusern auf einen Durchschnittspreis von 180 $ pro Quadratfuß.
Damit können wir dann zumindest grob sagen, dass beim Durchschnittspreis von 180 $ das Haus 360.000 Dollar kosten müsste.
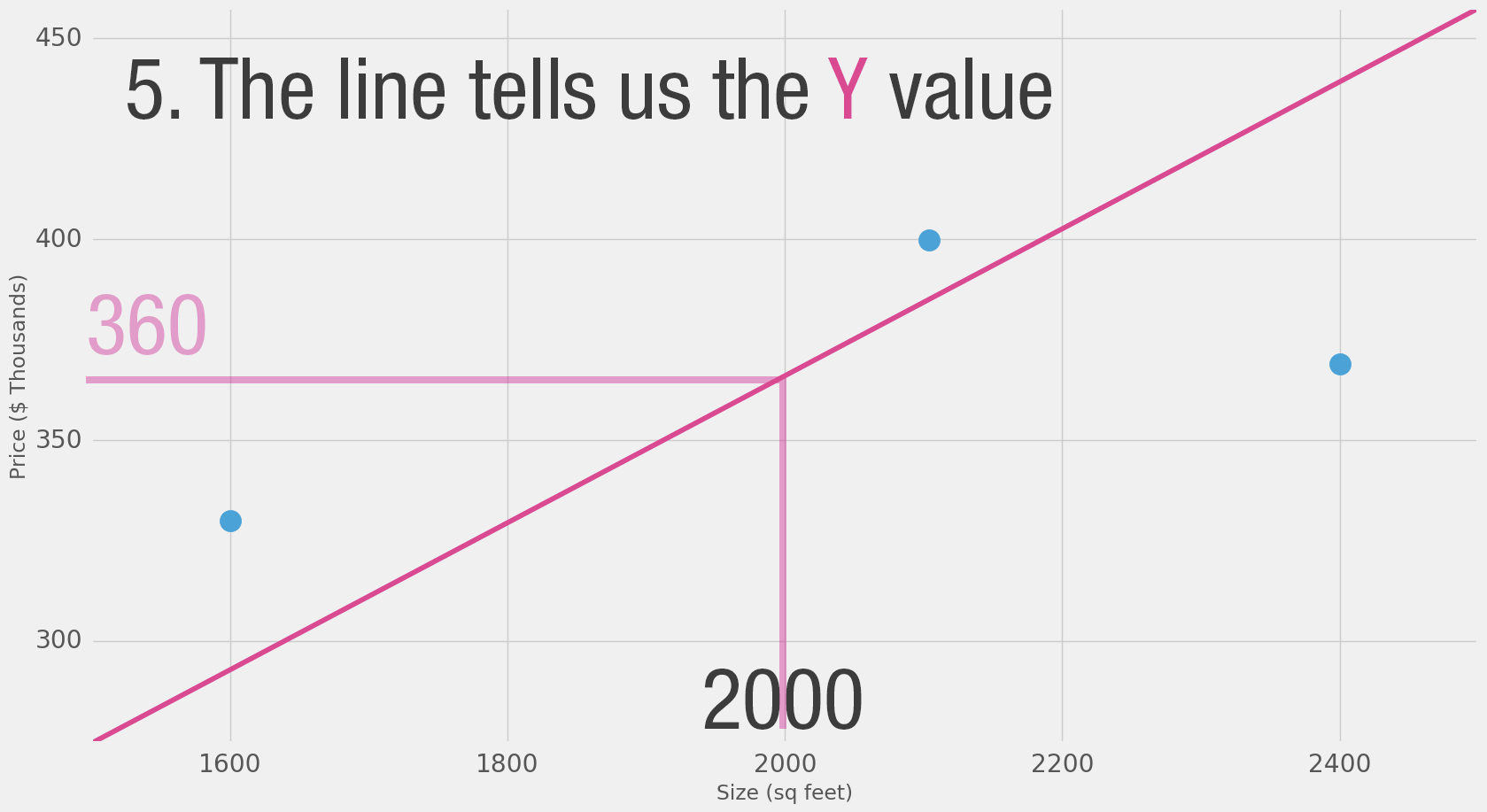
Man kann das Ganze auf einem Koordinatensystem darstellen.
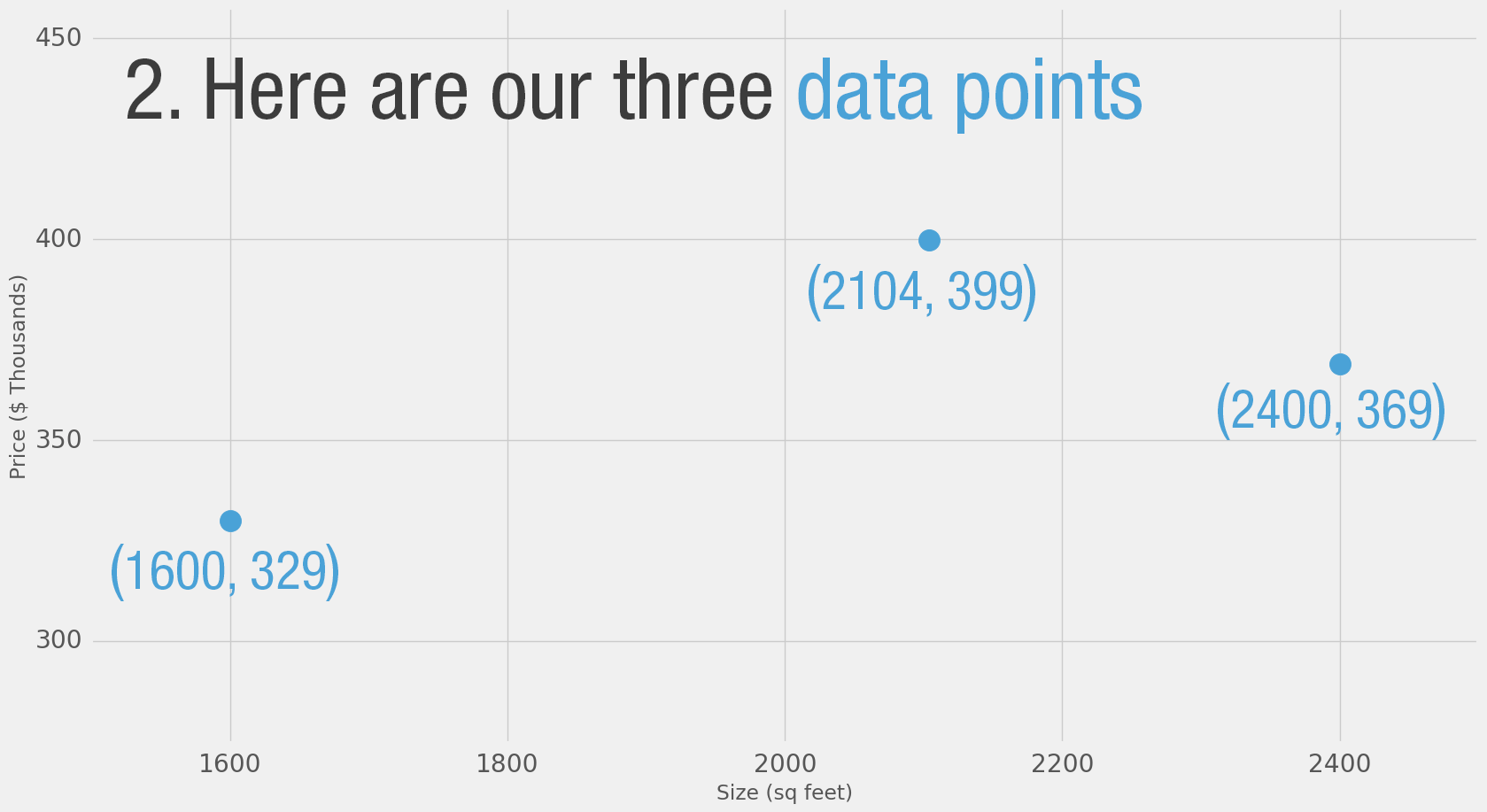
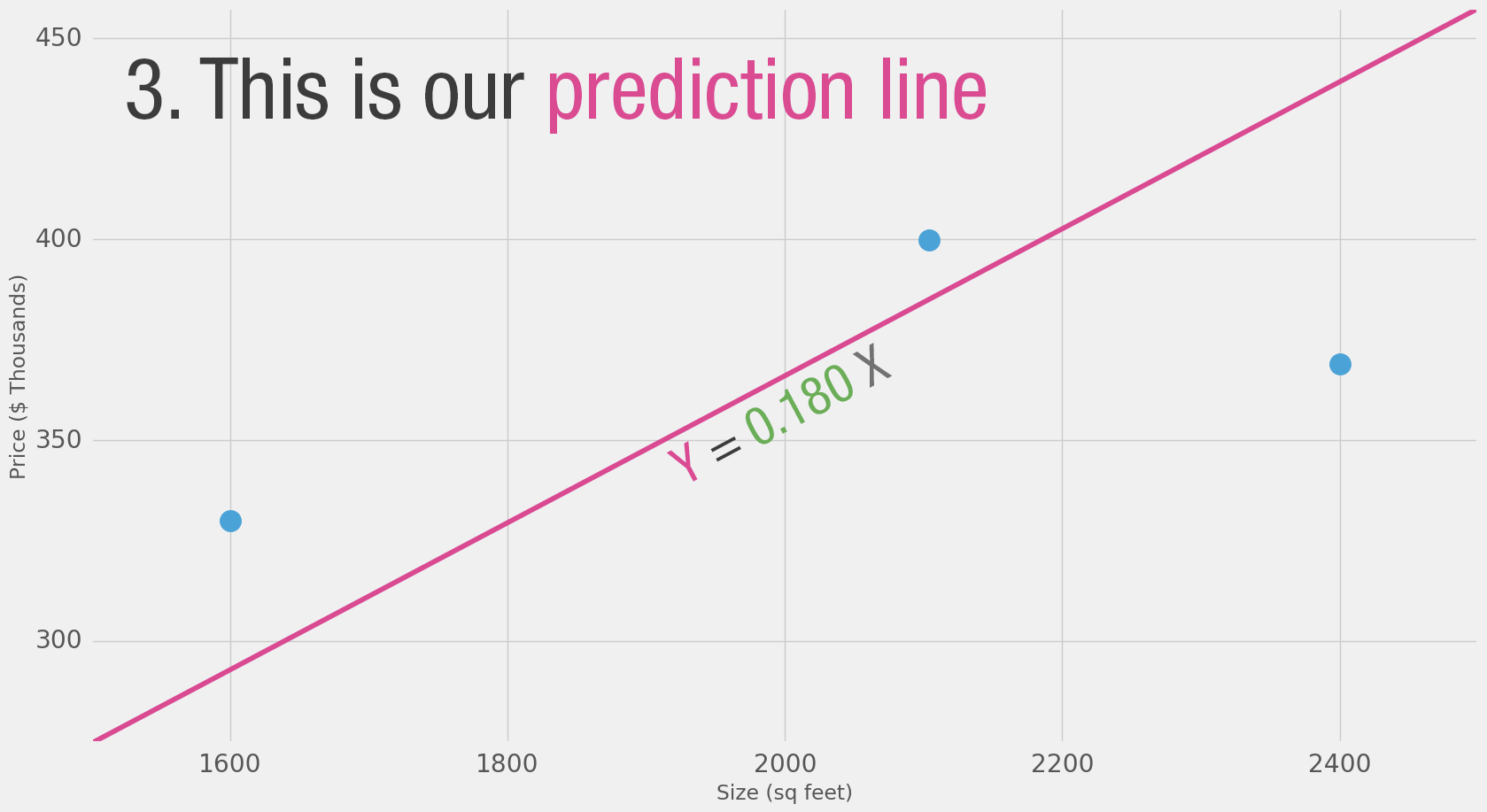
Bei 2.000 Quadratfuß müste der Preis bei 360.000 $ liegen - wenn es nur nach dem Durchschnittspreis geht.
"X (Quadratfuß) mal 180 (Durchschnittspreis) = Hauspreis"
Einfache Mathematik, die man gut nachvollziehen kann - das ist quasi der erste Schritt.
Mit solchen Eingaben (Werte plus Ergebnisse) werden die Modelle trainiert.
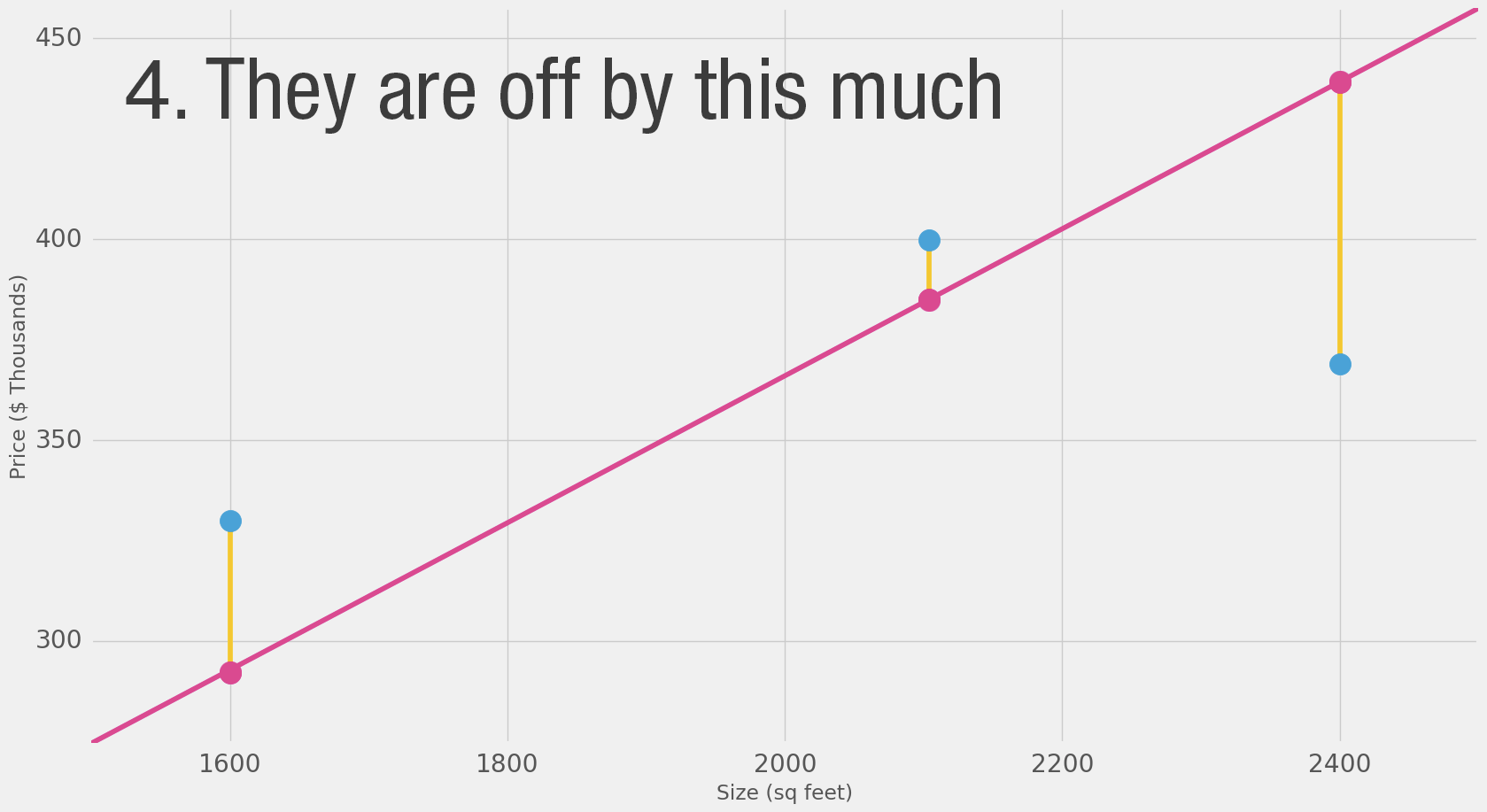
Wir erkennen aber auch die Abweichungen vom Durchschnitt
Und die Abweichungen sind nach unten wie nach oben durchaus beachtlich.
Die Vorhersage hier ist eine einfache Multiplikation.
ABER: wir mussten entscheiden, wie wir zu dem Ergebnis kommen.
Die 'einfache' Mathematik, die man gut nachvollziehen kann - ist nur der erste Schritt.
Wie also weitermachen?
Welche Möglichkeiten gibt es, den durchschnittlichen Abweichungswert und damit dann auch die Vorhersage zu verbessern?
In diesem Fall wird ein rechnerischer Abweichungswert gebildet.
Weil es statistisch nur um die Abweichung geht und es dabei nicht entscheidend ist, ob die Abweichung negativ oder positiv ist, wird der Wert so gebildet:
Abweichungswert = Abweichung im Quadrat (negative und positive Werte werden positiv)
Für den ersten Hauspreis heißt das:
Abweichung (21) im Quadrat = 441
Für den zweiten Hauspreis heißt das:
42 im Quadrat = 1756
Für den dritten Hauspreis heißt das:
-63 im Quadrat = 3969
Hinweis Auf der Quellhomepage hat sich ein Fehler eingeschlichen (der Abweichungswert für den ersten Preis stimmt nicht ganz).
Wenn wir also ein besseres (statisches) Vorhersagemodell wollen, müssen wir schauen, dass die durchschnittliche Abweichung geringer wird.
Wie können wir das erreichen?
Erster Weg: Wir passen den Durchschnittspreis an.
Also, was kann man noch machen?
Wir haben durch eine kleine Anpassung des Durchschnittswert zumindest eine leichte Veränderung der Abweichung gemerkt.
Mit dem veränderten Durchschnittswert haben wir die 'Gewichtung' verändert.
Bei der grafischen Betrachtungsweise haben wir die Steigungslinine dabei verändert.
Für weitere Anpassungen müssen wir jetzt zusätzlich eine Veränderung an der Linie ergänzen.
Wie das?
Um im Bild Immobilien zu bleiben:
Ein Haus mit 100 qm Fläche ist nicht 10x teurer als ein Haus mit 10 qm.
Ein Haus mit 1.000 qm Fläche ist nicht 10x teurer als ein Haus mit 100 qm.
Immobilien haben zwar einen Quadratmeterpreis, der (theoretisch) linear ansteigt und es gibt eine Art Grundpreis.
Natürlich sehr vereinfacht gesprochen.
Wir fügen also diesen 'Grundpreis' hinzu, der die ganze Linie anhebt. Das ist die 'Voreingenommenheit' oder der 'Bias'.
Und gleichzeitig wird der Preis, der pro qm berechnet wird, verringert - weil der Grundpreis ja immer mit dabei ist.
Damit verändern sich Anstieg und Gesamthöhe der Linie im Koordinatensystem.
Mit dieser Steuerung lässt sich dann die durchschnittliche Abweichung anpassen und positiv beeinflussen - das Ergebnis für die Einschätzung wird besser.
Auf der Beispielseite kann man das ausprobieren.
Wie wir gesehen haben, lässt dieser Prozess sich automatisieren.
Das nennt man den Gradient Descent, einen speziell darauf ausgelegten Algorithmus.
In unserem Falle wird die Abweichung auf bis unter 450 verringert - benötigt dafür aber mehrere hundert Durchläufe.
Aber wir können in diesem Beispiel die rechnerische Abweichung nicht auf Null bringen!
Aber wozu das Ganze?
In unserem kleinen Beispiel geht es um zwei Faktoren (Größe & Preis).
Schon beim Hauskauf sind dutzende weitere Faktoren denkbar, die mit berechnet werden können wie z.B. Größe des Gartens, Anzahl der Zimmer, Anzahl der Bäder, Garage ja oder nein, Solaranlage ja oder nein, Farbe, Beschaffenheit der Böden....
Ersetzen wir jetzt die Faktoren vom Hauskauf durch Tokens in einer Eingabe, wird klar, wie komplex die Berechnung dann wird.
Gewichtung und Bias
Die beiden Begriffe sind uns gerade begegnet mit der Beeinfussung (der Gewichtung) des eigentlich berechneten Quadratmeterpreises und...
... der Annahme, dass es einen Grundpreis gibt (dem Bias oder der Voreingenommenheit).
Diese beiden Faktoren sind für die Ergebnisse von generativen Modellen entscheidend!
Neben den verwendeten 'Lernquellen'.
Und wir sind hier noch bei der Erkennung der Eingabe - noch nicht bei der Ausgabe von Ergebnissen einer Anforderung an ein LLM (oder anderes generatives Modell).
Bei LLMs entspricht die Anzahl der eingegebenen Tokens der Anzahl der Faktoren, die zueinander in Beziehung gesetzt werden, um eine Eingabe zu erkennen und eine entsprechende Ausgabe zu tätigen.
Die Abweichung kann zwar minimiert werden - kann aber dabei Null nie erreichen.
Darum lässt sich das Bullshitting von LLMs auch niemals ganz ausschalten.
Und wie entsteht dann die Ausgabe?
Der nächste Schritt ist die Berechnung des nächsten Tokens.
Und hier sind wie beim Geschäftsgeheimnis der Hersteller von LLM - die Art der Berechnung ist in der Regel nicht einsehbar.
Aber klar ist - für jeden Token wird die Wahrscheinlichkeit des nächstgelegenen Tokens berechnet.
Bei der Ausgabe wird dann entschieden, ob der wahrscheinlichste oder einer der wahrscheinlicheren (nach festgelegten Prinzipien) verwendet wird.
Da in den meisten Modellen jeweils nicht der wahrscheinlichste verwendet wird, unterscheiden die Ausgaben sich bei jeder Eingabe - auch wenn die Eingabe gleich bleibt.
Ein Faktor dafür, dass man den Maschinen unterstellt, angepasst zu reagieren.
Versuche die Ergebnisse besser zu gestalten
Man versucht, die Ergebnisse zu verbessern, indem man die Endprodukte der Ausgabe dann erneut überprüfen lässt.
Die Berechnungen dazu nennt man dann 'reasoning'.
Das Reasoning findet heute in der Regel mit den fertigen Ergebnissen statt, es ist geplant, dass es in die Modelle direkt bei der Berechnung eingebaut werden wird - wann und wie genau das funktioniert, ist nicht öffentlich.
Macht KI Fehler?
Nein, denn es basiert ja nur auf Berechnungen.
Ja, denn es sind ja absichtlich Unschärfen eingebaut und die Informationsquellen sind nicht immer korrekt.
Disclaimer
Die Darstellung hier ist eine vereinfachte.
Wer sich technisch weiter damit beschäftigen möchte, findet dazu zwischenzeitlich viele wissenschaftliche Arbeiten.
... die ich zum Gutteil auch nicht verstehe!
Das Missverständnis des Verstehens
Welches Verständnis hat KI von der Welt und sich selbst?
Ein Beispiel:

Mögliche Assoziationen
Gelb
Mauer
Blume
Allergie
Sonnenblumenkerne
usw.
Unser Eindruck ist geprägt von persönlichen Erfahrungen
Gute Bilderkennungssysteme würden beschreiben können, was zu sehen ist.
Aber damit verbundene persönliche Assoziationen kann keine Maschine haben.
Obwohl man einen Algorithmus anlernen kann, welche Empfindungen möglich sein könnten bleibt die Erfahrung immer etwas menschliches.

Die Assoziation rot käme bei einer KI nicht vor.
* und jetzt wird es spannend *
Wie sieht eine KI sich eigentlich selbst?

Das System stellt sich hier vermenschlicht dar!
Warum?
Wie gehen wir als Gesellschaft damit um?
Die Firma hinter diesem System gibt an, besonders verantwortungsvoll mit der Technik umzugehen.
"Anthropic PBC ist ein US-amerikanisches Unternehmen im Bereich künstliche Intelligenz (KI), ... Es hat sich auf die Entwicklung von allgemeinen KI-Systemen und Sprachmodellen spezialisiert und setzt sich für einen verantwortungsvollen Umgang mit KI ein."
Break!
KI und Recht
Vorweg: Auch wenn wir den EU-AI-Act und andere Regelungen haben, sind viele Fragen, die den juristischen Umgang mit KI betreffen, noch lange nicht geklärt.
Disclaimer: Ich bin (glücklicherweise) kein Jurist.
KI und Recht
Es ist relativ klar, dass in den nächsten Jahren noch viele Prozesse um alle möglichen Faktoren bei KI geführt werden.
Daher hier nur ein paar wenige Punkte.
KI und Urheberrecht
Wem gehören die Rechte an Dingen, die durch KI generiert werden?
Antwort:
Niemandem
Die Voraussetzung für Urheberrechte und dem damit verbundenen Schutz ist, dass es ein natürliche Person als Urheber*in gibt.
Um dem Urheberschutz zu unterliegen muss der menschliche Anteil am Ergebnis substantiell sein, die Eingabe eines Prompts reicht dazu nicht.
Aber:
Komplex wird es, wenn der Prompt das Nachgestalten eines geschützten Bildes oder Textes vorgibt.
Z.B. ich gebe vor, dass eine Szene aus Harry Potter gemalt werden soll.
EU-AI Act
EU-Gesetz zu europaweiten Regelungen zu Künstlicher Intelligenz.
Vorangestellt sind 180 'Erwägungsgründe, die meisten davon eine Begründung was und warum überhaupt geregelt wird.
Gesetz gilt ab 2. August 2026.
Verbote und die allgemeinen Bestimmungen seit dem 2. Februar diesen Jahres.
Was wird denn aktuell so diskutiert
Beispiele zur Diskussion & Frageansätze
Wie wollen wir denn als Gesellschaft mit KI umgehen?
Was überlassen wir Maschinen und Algorithmen?
Was lassen wir lieber beim Menschen?
Fazit dieser Fragen?
Nimmt uns KI (und andere Technologie) Dinge ab?
Lassen wir die Entscheidungen lieber bei uns?
Mein Fazit: Technik löst keine sozialen Probleme.
Wird aber immer wieder probiert.
Offboarding
Und, platt?
;-)
Was für Fragen bleiben noch?
Wünsche für weitere Treffen/Online-Workshops?